

Here’s the question of the hour. Can you use serverless Elasticsearch or OpenSearch effectively at scale, while keeping your budget in check? The biggest historical pain points around Elasticsearch and OpenSearch are their management complexity and costs. Despite announcements from both Elasticsearch and OpenSearch around serverless capabilities, these challenges remain. Both of these tools are not truly serverless, let alone stateless, hiding their underlying complexity and passing along higher management costs to the customer.
Let’s look at some of the key serverless definitions and challenges of log management in a serverless architecture. Which tools are truly up to the challenge of performance at scale, while keeping costs in check?
What is a serverless architecture?
A serverless architecture is a way to build and run applications without managing servers. While applications still run on servers, the cloud service provider (e.g. AWS or GCP) manages the underlying infrastructure. Adopting a serverless architecture promises faster time to market, scalability, and lower costs. Paired with cloud object storage, serverless architectures have made databases more natively scalable and available.
Evolution toward a serverless, stateless database architecture
Over time, cloud-based, distributed databases and their underlying architecture have evolved through three major phases. Let’s call the pre-cloud database era architecture zero, where siloed databases only scaled to meet the capacity of your local machine. Since then, newer cloud-native, serverless, and stateless generations of databases have emerged to provide better scalability and higher performance at lower cost.
Generation 1: Large-scale distributed databases
First-generation databases like Elasticsearch and OpenSearch were built with a large-scale viewpoint, as individual databases connected via a synchronization protocol. Each node within a computer cluster works within a group, but executes in isolation and synchronizes state amongst its peers within a quorum. A key part of database state synchronization is division of work across the cluster. In other words, concepts like partitioning data into shards during ingestion, as well as querying those shards, is a major construct in such architectures.
By their very nature, these databases are as “stateful” as you can get, since they depend upon numerous pieces of the system to remain in persistent state. Storage and compute are still tightly coupled, even though a sharded architecture helps with scale. To conduct an operation such as querying or synchronization in these databases, you must read off a disk, put compute in RAM, and hold state.

Generation 2: Serverless databases
The second generation of distributed databases, such as Snowflake, adopt a shared storage layer and serverless architecture. The serverless architecture separates storage and compute, and allows for a different way to scale. The key difference between Generation 1 and Generation 2 is a shared storage layer that any compute node can talk to. Because of the serverless architecture, you can spin up additional compute at any time, write globally, and talk to any aspect of storage — without the need for sharding or partitioning.
While these databases remove some key frustrations of first-generation databases (mainly resolving key data replication issues) there are still problems with ingestion and querying. Second-generation databases read off of global storage and hold state in compute. This compute cannot be reused, meaning these databases are not truly stateless. For example, you’re likely pulling data from object storage and keeping it in RAM in a second-generation database if you want your query to be fast.
Generation 3: Serverless and stateless databases
Third-generation databases, such as ChaosSearch, embrace a globally shared storage viewpoint that leverages cloud object storage (e.g. Amazon S3 or GCP). These databases separate storage from compute, so they’re serverless. They’re also stateless, since they let go of state when they conduct an operation like ingestion or querying. Stateless database architectures have the advantage of better cost/performance, increased scalability, and higher availability than their first- and second-generation counterparts.
In a stateless architecture, the state of a previous transaction does not persist in subsequent transactions. Both client and server requests and responses are made in a current state. In the distributed database world, that means any node within a quorum can instantly and independently work on any aspect of a database workload at any time. Nodes don’t communicate state directly, but leverage strongly consistent and distributed storage such as Amazon S3 or Google GCS as point of synchronization, as well as deterministic controls / procedures. In other words, cloud object storage provides both a location to store data, as well as to synchronize state.
While serverless and stateless architectures have clear advantages, it’s not easy to migrate from Generation 1 or 2 to Generation 3. Both Elasticsearch and OpenSearch are demonstrating how hard it is to move from a stateful to a serverless and stateless architecture — without rewriting from scratch.

Are Serverless Elasticsearch and OpenSearch effective?
In late 2022 and early 2023, both Elasticsearch and OpenSearch announced serverless options for customers. The goal of these options was to reduce the management complexity associated with these services, simplifying ingestion and lowering the cost of retention. Despite the promises, both the new OpenSearch Serverless offering and the pending Elasticsearch serverless architecture changes fall short — essentially masking existing complexity with “serverless-ish” solutions.
Both Elasticsearch and OpenSearch are migrating their existing, first-generation architectures to second-generation serverless architectures. Elasticsearch users today are familiar with the problem of having to duplicate index data across multiple availability zones. Duplicating and moving data is meant to provide redundancy in case of outages. If something goes down and you have your data in hot storage, you lose access to it. Not ideal, since the lower tiers of storage are less performant, in the event you need to access or query it.
Let’s say you’re troubleshooting a persistent issue in your system, and you need access to data beyond a 30-day window. Finding the root cause of the problem in Elasticsearch is a major management pain. You never know the exact data you need to access from cold storage or other storage tiers to solve the problem. And because Elasticsearch is built on top of the Lucene search interface, many users experience issues with performance.
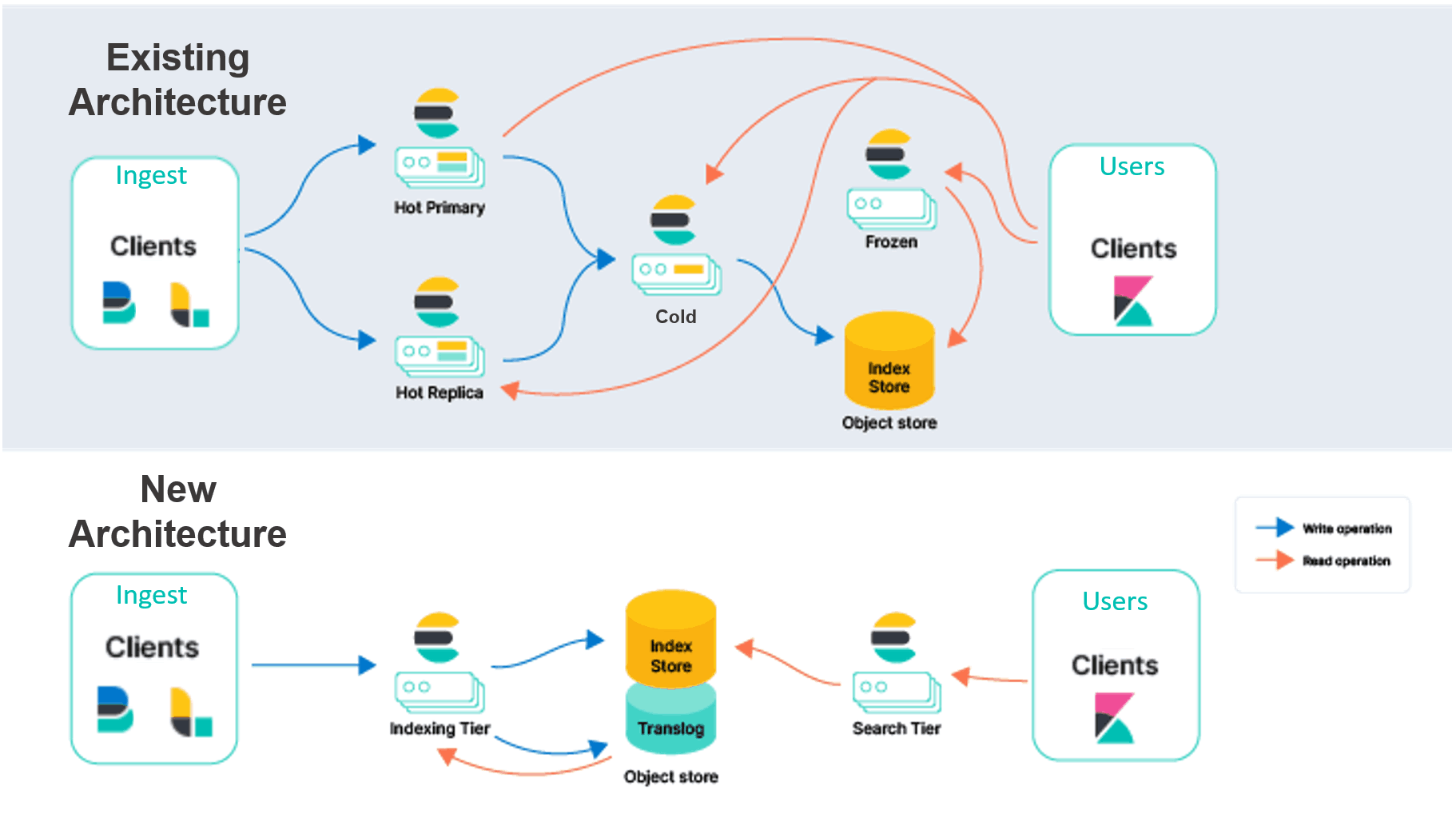
Challenges with underlying data representation and data architecture
The proposed serverless Elasticsearch workaround, which was replicated by OpenSearch Serverless, is to save data directly to Amazon S3. The problem is that both the underlying data representation and data architecture are still preventing a full migration from Generation 1 to Generation 2. Both Elasticsearch and OpenSearch still rely on replicas for performance and failover purposes. Plus, ingestion and other transactions like querying still require a persistent state.
In addition, both Elasticsearch and OpenSearch rely on Lucene as the underlying engine. Lucene is known for not being performant in object storage. That means you’ll still need a way to keep data in memory to increase performance, which adds costs. It’s not well-designed for serverless and stateless implementations. By its very nature, Lucene gets too big to be fast in object storage, which has forced both Elasticsearch and OpenSearch’s hands when it comes to legacy architecture decisions.
Whether you’re using OpenSearch Serverless, which is available now, or Elasticsearch Serverless, which is promised for the future, you’ll face the same issue. There’s still too much complexity. With the same Lucene engine under the hood, querying data in object storage will be slow, while querying in-memory will be fast. That means you’ll need to scale memory to keep your service working fast.
Another problem users are finding is that OpenSearch serverless doesn’t auto-scale. This means you’ll need to overestimate compute capacity to make sure your service stays up. As with previous versions of Elasticsearch and OpenSearch, database management and storage setup is still a challenge.
A truly serverless, stateless log analytics alternative
While many services strive for a stateless, serverless architecture, there’s one big problem. If you keep the same data representation like Elasticsearch and OpenSearch do, you’re hiding complexity from the end user and passing along added costs. The alternative is to choose a truly serverless and stateless, third-generation database like ChaosSearch.
ChaosSearch is designed upfront to be stateless and serverless, decoupling storage from compute. The Chaos Fabric® stateless architecture brings together storage, compute, and services layers to provide independent and elastic scaling for added scalability. That way you can eliminate the cost vs. data retention tradeoffs you face with services like Elasticsearch, and stop moving data.
Since the relationship between storage and compute in ChaosSearch is so dynamic, you can add or delete workloads at any time without having to repartition data. By using AWS S3 or GCS, you don’t need to store data in memory —while still keeping your search queries performant and reliable. That’s because Chaos Index® creates a compressed representation of your cloud object data, making it easier to index data and search/query it at scale — at a fraction of the cost of Elasticsearch or OpenSearch.
Want to learn more about ChaosSearch’s serverless architecture?

