

Chaos LakeDB
Built from the ground up to transform your cloud storage into a Live Search+SQL+GenAI Analytics Database

Unified Live Data Lake
Live operational and business use cases all leverage the same type of data - now you can collapse them into a single analytic database!
Observability and Security Analytics without retention limits at a fraction of the cost, plus User Insights in real-time across the organization, all enhanced with a natural language assistant powered by GenAI.

Product White Paper

Transform you cloud storage into stateless live analytics database
UNIFIED
INTEGRATED
FORMAT
Same on Disk and in Memory

STRUCTURE
Same for Search and Relational

ALGORITHMS
Generic Execution Across Access

ARCHITECTURE
Stateless and Auto‑Scalable



Compression through Representation
Split information into 3 different dimensions to reduce size and entropy

Symbols
Efficient Symbol Encoding (Text-Search)
Manifest
Efficient Scope Routing (Query Planner)
Locality
Efficient Locality of Reference (Relational)
Multiplicity of Small
Performant Search+SQL
Optimized for Live Data
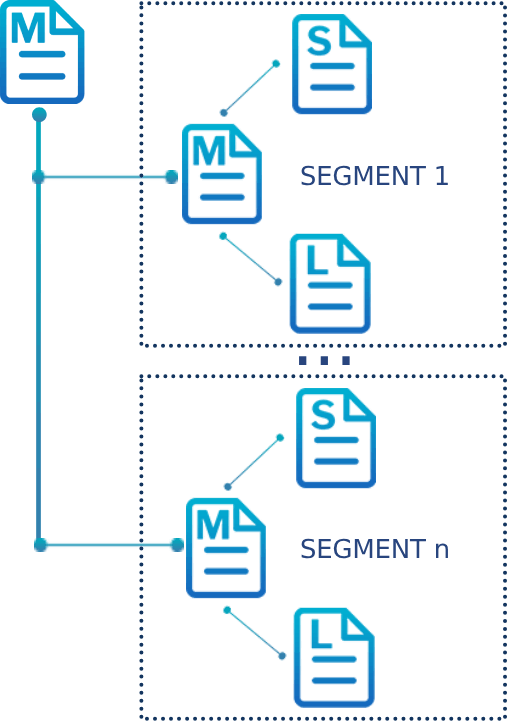
Organize data into streams of segments organized by groups, accessible by views
Auto detect and dynamically map schema and tokenize all data
Object Group (OG)
Live Analytics

No Schema Management

Cloud Storage as Backend, not Storage
Segments purposefully designed for fast performance straight from cloud storage
Same format and structure on disk as in memory
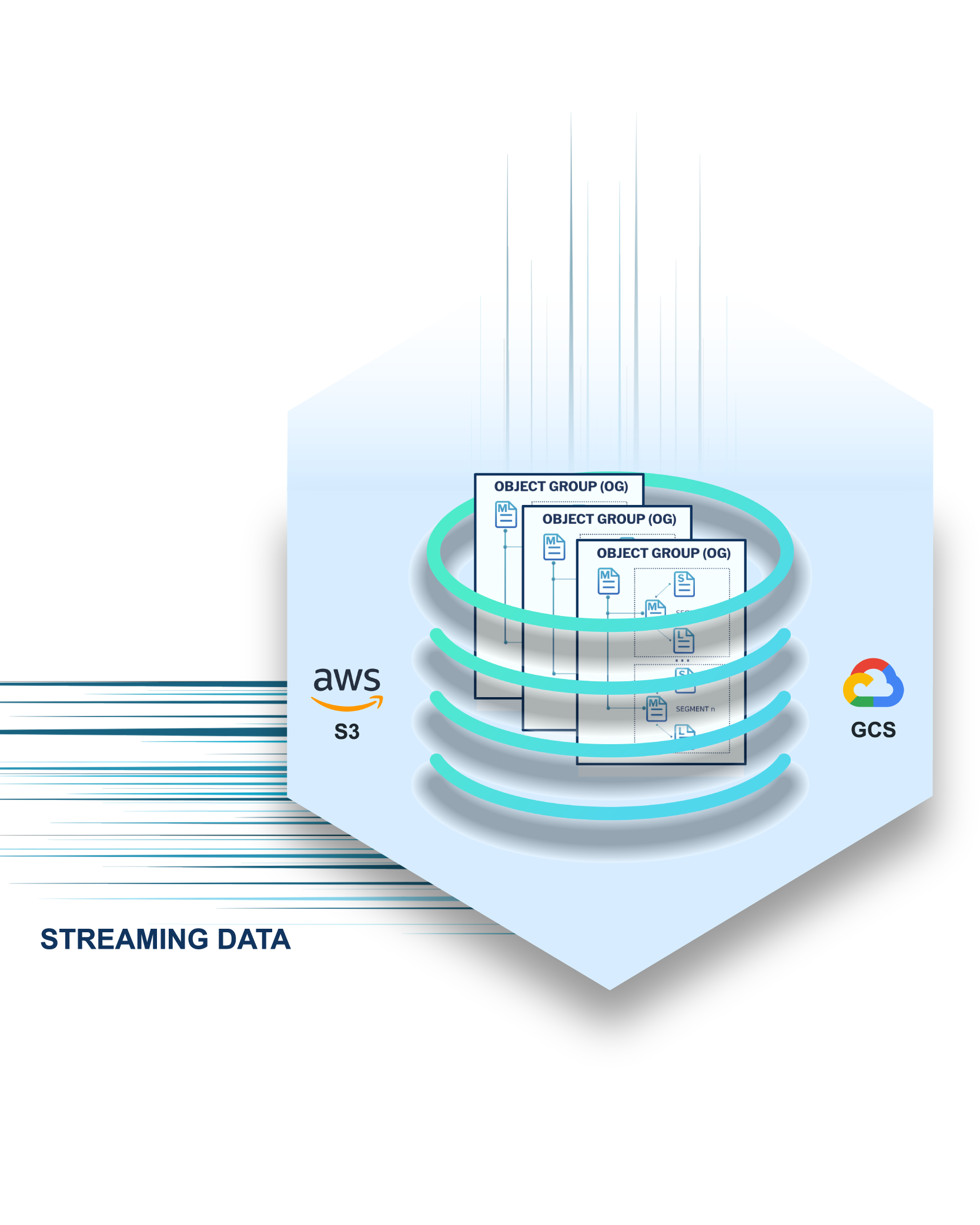
Best of Cloud Storage

Enables Stateless

Serverless and Stateless Fabric
Compute used only to ingest and query data, not data persistence / cache
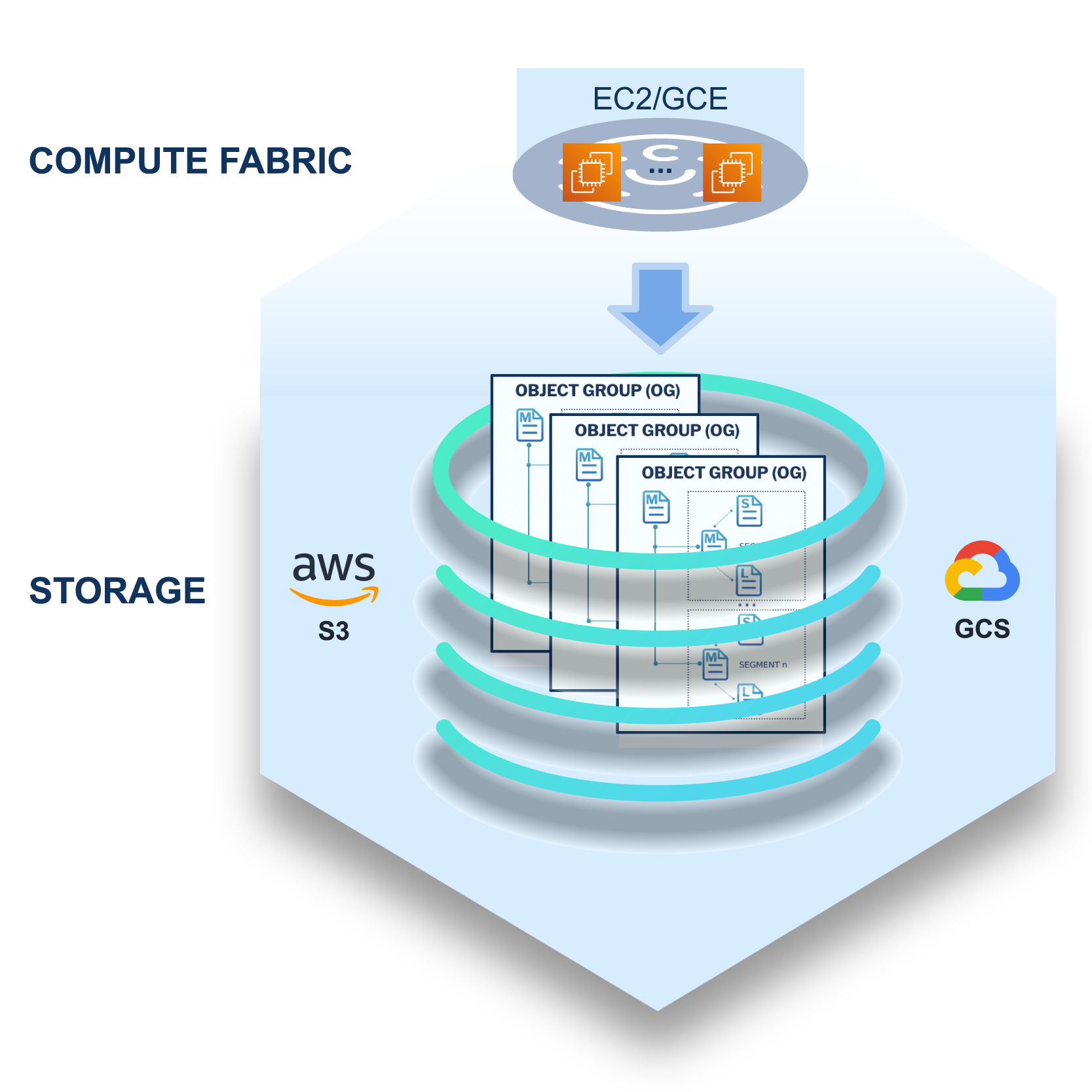
No Cost-Retention Trade-off

Compute used just for processing, not persistence and all data in cloud storage
Fast First Read

All queries read from cloud storage reducing first read latency penalty
Generic Compute Workers
Generic containerized workers can do any ingestion and query task

Optimized Utilization for Cost-Performance

Any worker can be used and leased for any ingestion or query task
Scale without bottlenecks

Workers auto age-out to keep them always fresh. Workers auto-scale based on overall worker needs (Chaos Farm)
Distributed Stream Ingestion and Querying
Distributed stream ingestion Distributed query execution
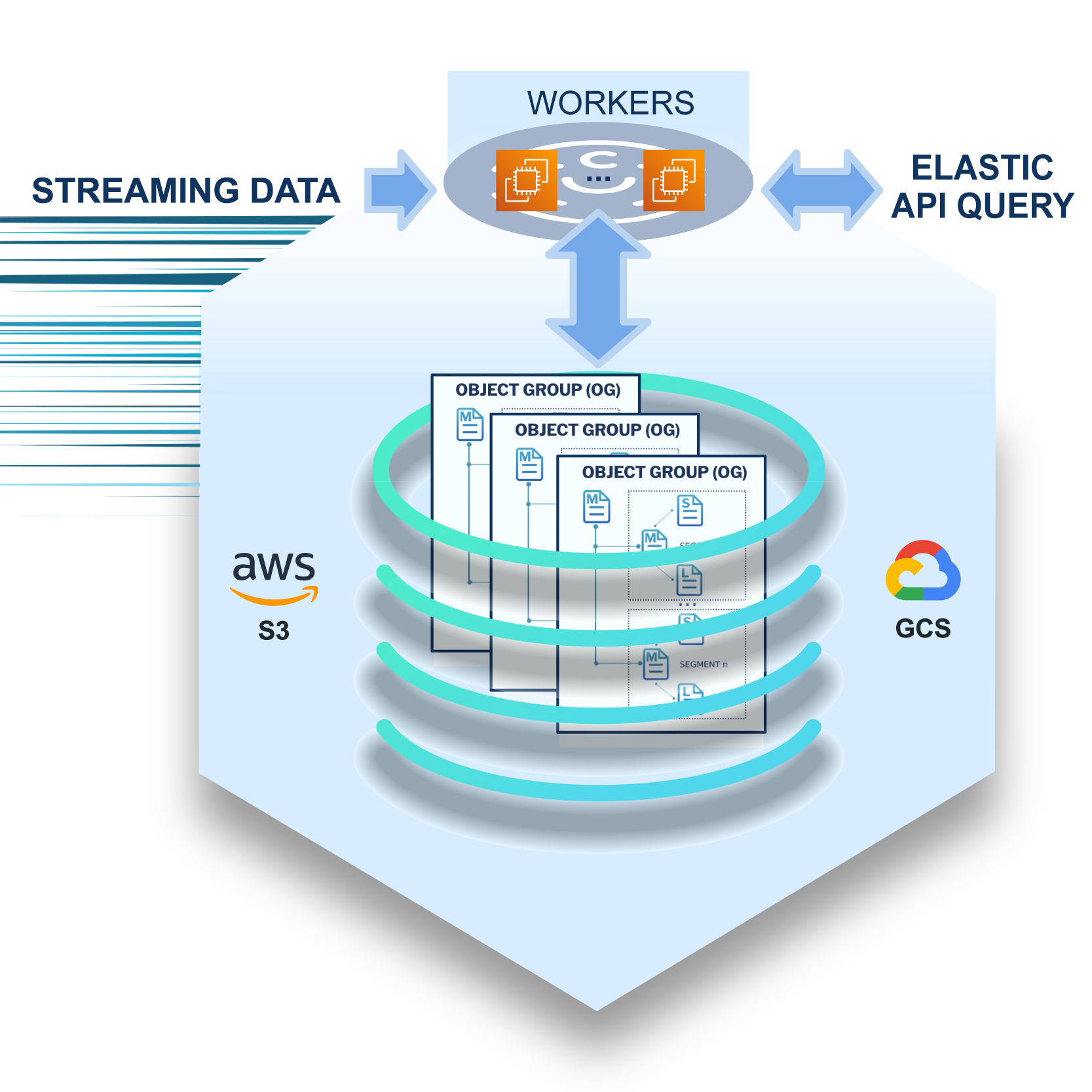
Live Ingestion
at Scale

Efficient live data ingestion that can auto-scale to handle any spikes
Search+SQL Analytics via Virtual Views

Integrated Generic Query Engine Chaos Index delivers efficient Search+SQL with Virtual Views for Democratized Data Access
Distributed Work Operating System
Orchestration and Scheduling of Distributed Work for Ingest and Query task
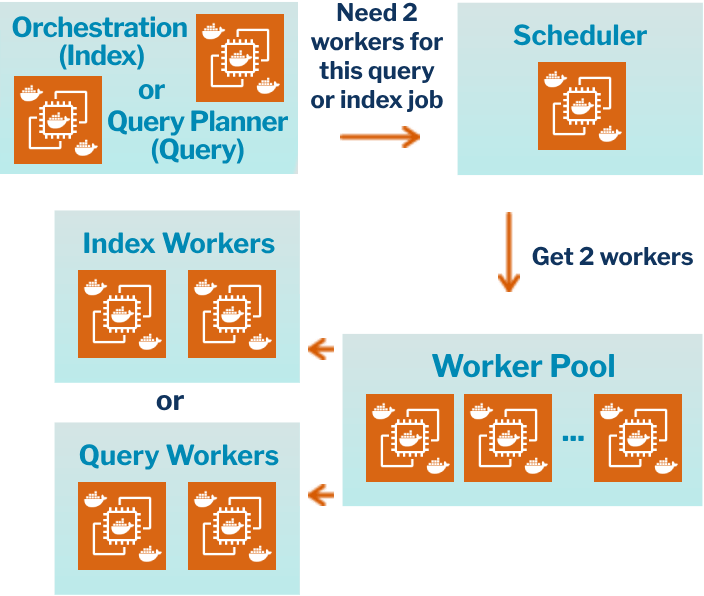
Best-in-class Cost-Performance

Distributed worker allocation for improved utilization leveraging generic workers
Improved
Experience

Worker allocation prioritized to improve customer experience
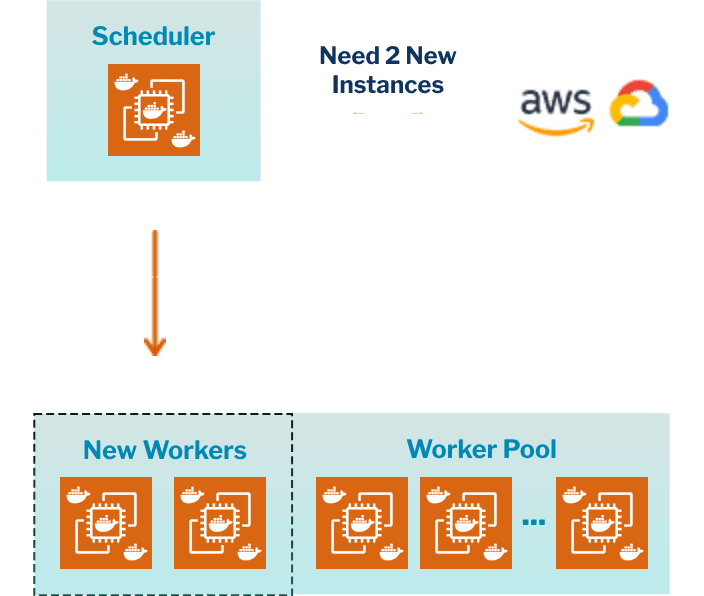
Auto-Scalable
Compute
Auto-Scalable Compute Worker Pool Based on Policies and Utilization
Leverage the best of stateless

Ability to scale compute up in high usage periods and down in low usage ones
Intelligent Auto-Scale for Improved Cost

Ability to schedule scaling based on time / activity or dynamically based worker utilization
Centralized Farm to Support Multiple VPCs
Centralized Farm can hold compute for multiple VPCs (customers) without sharing
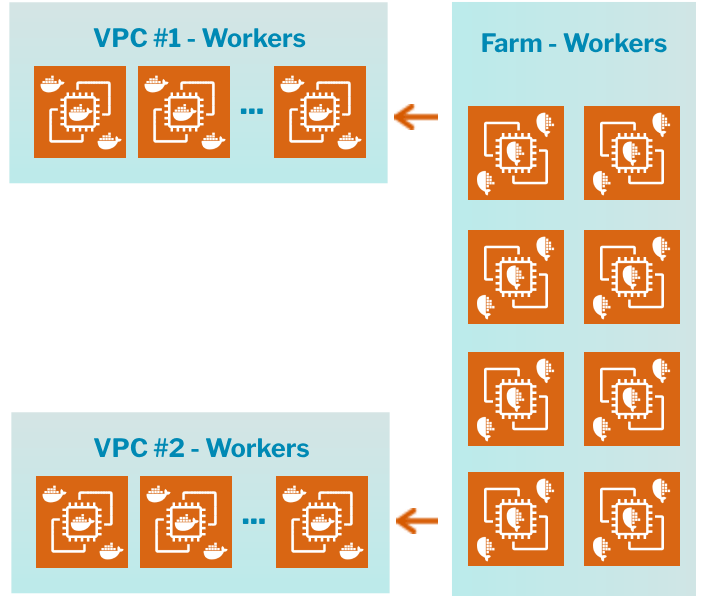
New Cross-VPC Compute Movement

Ability to move compute across VPCs allows for centralization of compute that can securely be accessed by multiple VPCs
Reduced Time to Compute

Ability to access compute from another VPC allows for latency of seconds to scale rather than minutes from provider




Future-Proof Your Analytics at Scale
