
Databricks is lighting the way for organizations to thrive in an increasingly AI-driven world.
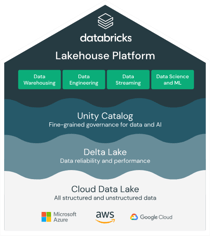 The Databricks Platform is built on lakehouse architecture, empowering organizations to break down existing data silos, store enterprise data in a single centralized repository with unified data governance powered by Unity Catalog, and make the data available to a variety of user groups to support diverse analytics use cases.
The Databricks Platform is built on lakehouse architecture, empowering organizations to break down existing data silos, store enterprise data in a single centralized repository with unified data governance powered by Unity Catalog, and make the data available to a variety of user groups to support diverse analytics use cases.
But despite the promises of data centralization, increased data sharing, and eliminating data silos, organizations using Databricks for log and event analytics use cases often encounter specific challenges in the Databricks platform that lead them to implement solutions like OpenSearch or Elasticsearch alongside Databricks to enable log management for analytics use cases.
In this blog post, we’re looking at some of the key challenges associated with querying log and event data in Databricks. You’ll discover the five most common challenges organizations face when using Databricks for log management and analytics, plus how to overcome those challenges and better support log analytics use cases inside your Databricks lakehouse.
Read: Top 7 Mistakes that are Hindering Your Log Management Strategy.

5 Key Log Management Obstacles for Querying Data in Databricks – and Solutions
1. Managing Data Pipelines
Organizations with modern hybrid cloud infrastructures generate huge amounts of log and event data from multiple data sources on a daily basis. To query their log and event data in Databricks, these organizations must build and maintain data pipelines that extract the log data from its source, clean or transform the data to prepare it for analysis, and load the data into a Databricks Lakehouse.
Databricks users have two options when it comes to building data pipelines for their log and event data:
- Spark Structured Streaming, a stream data processing engine that allows users to build pipelines in Databricks using Spark APIs.
- Delta Live Tables (DLT), a declarative ETL framework that also allows users to automate many operational aspects of data pipeline management.
Both Spark Structured Streaming and DLT can make it easier for organizations to configure pipelines for log and event data. But as log volume and number of data sources increases, the number and complexity of pipelines also increases and organizations can end up spending significantly more time and resources on maintaining data pipelines, manually updating transformation logic, remediating performance issues, and other pipeline management tasks.
Organizations can sidestep the challenges of data pipeline management by integrating Databricks with an external query engine that can analyze data in a schema-on-read approach with no data movement or complex ETL processes.
2. Parsing Diverse Log Formats
Another challenge associated with querying log and event data in Databricks has to do with the diversity of data formats used for logging, and more specifically the challenge of dealing with structured, semi-structured, and unstructured logs:
-
Structured logs follow a consistent data format that’s less read-able for humans, but easier for machines to parse, search and filter, or tabulate to enable relational/SQL querying.

Structured logs like this JSON log write data using key-value pairs that are easier for computers to parse and tabulate compared to unstructured logs.
- Semi-structured logs contain a mixture of structured and unstructured data. They are more read-able for humans than structured logs, but variability in their formatting makes semi-structured logs less consistent and more complex for machines to parse or tabulate for querying purposes.
- Unstructured logs are typically written as plain-text messages. These logs are easily read-able for humans, but the lack of a formal data structure can make it difficult to process or tabulate unstructured log data using automated data pipelines.
Databricks Photon is a relational query engine that’s optimized for high-performance analytics on structured data. So while Photon may be well-suited and efficient for running SQL queries on structured log formats like JSON and LogFmt, it’s not as well-suited for parsing, tabulating, and querying semi-structured or unstructured logs with variable formats.
An effective way for Databricks customers to start supporting more diverse data formats for log analytics use cases is to integrate Databricks with a query engine with stronger native support for unstructured and semi-structured data types.
3. Handling Complex Log Data
Modern organizations are trending towards structured JSON logs, which is usually a good logging format to tabulate and query using Databricks Photon. However, some JSON logs contain more complex data structures like nested objects and nested arrays that create new log management and analytics challenges.
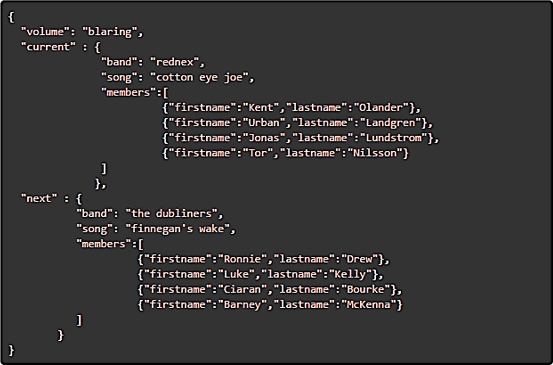
Complex JSON logs with nested or hierarchical data structures can be a challenge to query using Databricks Photon.
Nested JSON and other log formats with multi-level hierarchies require special transformations to flatten, join or un-nest the data before it can be analyzed. Handling these transformations manually can be prohibitively time-consuming at scale, while doing it with Databricks Photon introduces an additional layer of complexity to the data pipeline and slows down query performance. Nested JSON can also lead to log management challenges, including ballooning data storage costs and a messy database that makes it hard to write useful queries.
As organizations move towards JSON logging, dealing with the complexity of nested JSON has become a near-universal challenge for DevOps and data engineers. A great way to address this challenge is with JSON FLEX, a set of tools developed by ChaosSearch for extracting data from complex JSON logs without common drawbacks like row and column explosion.

4. Limited Query Support
Databricks Photon was designed to enable ultra-fast execution of relational queries on tabular data - not to support full-text search - but there are many log analytics applications that require full-text search:
- Threat Hunting - Enterprise SecOps teams use full-text search to filter through semi-structured and unstructured security logs, searching for suspicious patterns or specific keywords that could indicate a cyber attack.
- Cloud Observability - Cloud engineers use full-text search to query cloud logs for specific events or error messages that can indicate issues with the performance of a cloud-based service, microservice, or serverless application.
- User Behavior Analysis - Product and marketing teams can use full-text search to analyze user behavior and clickstream logs for user inputs, error messages, or behavior patterns that reveal insights into the customer journey, drop-off points, and overall customer satisfaction.
Databricks’ limitations around native support for full-text search has led many Databricks customers to establish an OpenSearch or Elasticsearch cluster that can deliver full-text search capabilities while the organization continues using Databricks Lakehouse for relational queries. This comes with a substantial increase to operational overhead, along with the additional storage costs of duplicating the same data across both data stores.
As an alternative to standing up an OpenSearch or Elasticsearch cluster, Databricks customers can overcome this challenge by integrating their Databricks Lakehouse with an external query engine with native support for full-text search.

5. Alerting Limitations
Organizations using log analytics for use cases like threat hunting, cloud observability, or user behavior analysis benefit significantly from robust, real-time alerting systems:
- SecOps teams want real-time alerts on suspicious or anomalous activity that could indicate a cyber attack.
- Cloud Observability teams want real-time alerts on usage spikes, system failures, or errors that could indicate cloud health/performance issues.
- DevOps and product teams want real-time alerts on anomalous user behaviors that could indicate application performance issues.
Purpose-built log analytics tools often feature robust alerting systems to support and enable these use cases, but Databricks is primarily designed for large-scale batch analytics - not for logs. Databricks SQL Alerts can be used to periodically run queries, evaluate the results against defined metrics, and send a notification or alert if a predefined condition or threshold is met - but Databricks lacks native support for real-time alerting or complex alerting with multiple conditions.
To overcome this challenge, Databricks users can integrate their Databricks lakehouse with a purpose-built log analytics or alerting platform that offers more robust features around real-time alerting and incident management.
ChaosSearch is Bringing Log Analytics Natively to Databricks
Databricks provides a modern lakehouse architecture that’s foundational in a data-driven world, but the Databricks Photon query engine wasn’t designed to support those log analytics use cases that need full-text search to efficiently filter through large volumes of unstructured or semi-structured data.
ChaosSearch for Databricks is a powerful new solution that can seamlessly fill the gaps and enable those vital log analytics use cases for Databricks customers.
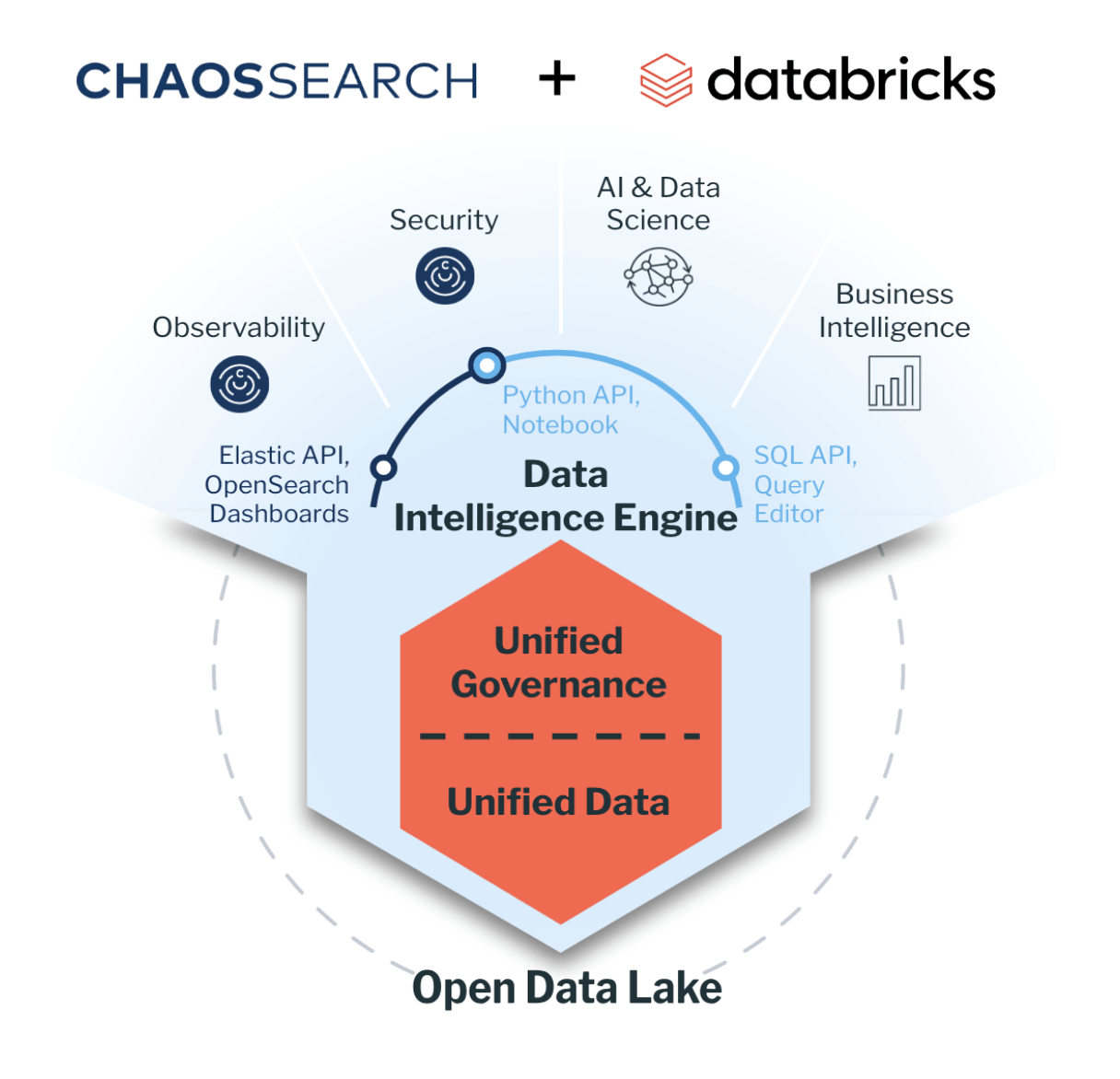
By integrating with Databricks, ChaosSearch is bringing log analytics use cases to the Databricks ecosystem and empowering Databricks customers to leverage security and observability data for AI/ML applications.
As a Databricks technology partner, ChaosSearch has ported our entire platform to run natively in Databricks. Databricks customers can stream data in its raw format directly into Delta Lake, where ChaosSearch can grab that data, index it with our proprietary data indexing and JSON FLEX technologies, and quickly make it available for full-text search, relational/SQL, or GenAI queries.
With ChaosSearch for Databricks, organizations can overcome the challenges of diverse log formats, JSON complexity, and limited querying support to streamline log management and enable log analytics use cases in Databricks without having to manage complex ETL pipelines or deploy additional database tools.
Ready to learn more?
Watch our free on-demand webinar Unleash the Potential of Your Log and Event Data, Including AI’s Growing Impact to learn more about the strategic advantages of using ChaosSearch for log and event analytics.
