

Started in 2009 as a research project at UC Berkeley, Apache Spark transformed how data scientists and engineers work with large data sets, empowering countless organizations to accelerate time-to-value for their analytics activities.
Apache Spark is now the most popular engine for distributed data processing at scale, with thousands of companies (including 80% of the Fortune 500) using Spark to support their big data analytics initiatives. As organizations increase investments in AI and ML technologies, we anticipate that Spark will continue to play a big role in the modern data analytics stack.
In this blog, we explore the evolution of Apache Spark, how the Spark framework is currently used on large data sets in the cloud, and our predictions for the future of Apache Spark in big data analytics.

What is Apache Spark?
The Apache Spark framework is an open-source, distributed analytics engine designed to support big data workloads. With Spark, users can harness the full power of distributed computing to extract insights from big data quickly and effectively.
Spark handles parallel distributed processing by allowing users to deploy a computing cluster on local or cloud infrastructure and schedule or distribute big data analytics jobs across the nodes. Spark has a built-in standalone cluster manager, but can also connect to other cluster managers like Mesos, YARN, or Kubernetes. Users can configure the Spark cluster to read data from various sources, perform complex transformations on high-scale data, and optimize resource utilization.
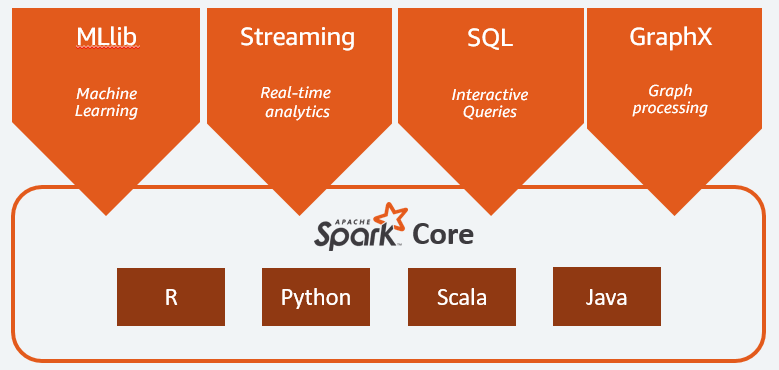
Apache Spark framework
The Spark framework consists of five components:
- Spark Core is the underlying distributed execution engine that powers Apache Spark. It handles memory management, connects to data storage systems, and can schedule, distribute, and manage jobs.
- Spark SQL is a distributed query engine for interactive relational querying.
- Spark Streaming is a streaming analytics engine that leverages Spark Core’s fast scheduling to ingest and analyze newly ingested data in real-time.
- Spark MLlib is a library of machine learning algorithms that users can train using their own data.
- Spark GraphX is an API for building graphs and running graph-parallel computation on large datasets.
Spark Core is exposed through an API that supports several of the most popular programming languages, including Scala, Java, SQL, R, and Python.

Hadoop MapReduce vs. Spark for Data Science
Before the development of Apache Spark, Hadoop MapReduce was the fastest and best option for parallel distributed processing of large datasets. Apache Spark was purpose-built to deliver faster and more efficient data processing compared to Hadoop MapReduce - and at a lower cost. Apache Spark improved on Hadoop MapReduce in two important ways:
- Faster Query Execution - MapReduce follows a rigid execution model with a strict sequence of map and reduce operations that often results in less optimized processing workflows. Spark’s Directed Acyclic Graph (DAG) execution engine is more flexible, resulting in more efficient operations and faster query execution.
- In-memory Processing - MapReduce writes intermediate data to disk after each reduce operation. This creates a high number of read/write operations, resulting in slow data processing times and reduced efficiency. Spark uses in-memory processing to store data during a job and re-use it across multiple parallel operations, reducing time spent on read/write operations and significantly accelerating data processing.
The result of these changes is massive gains in data processing efficiency compared to Hadoop MapReduce. Interactive SQL queries can be executed 10-100x faster on Apache Spark vs. Hadoop MapReduce.
How Does Apache Spark Power Big Data Analytics?
Fast data processing speeds at scale and support for multiple programming languages and diverse workloads have made Spark the engine of choice for big data analytics. Modern enterprises can deploy and self-manage Spark on public cloud infrastructure or in on-prem data centers, or consume Spark as a Software-as-a-Service (SaaS) offering via data analytics platforms like Databricks.
Let’s take a closer look at how Apache Spark is powering big data analytics across these three deployment models.
On-Prem Apache Spark
Spark is an open-source technology that’s free to download and deploy. Organizations can choose to deploy open-source Apache Spark in an on-premise data center. Running Spark on-prem requires the organization to establish a local Hadoop cluster, download and install Apache Spark on all nodes, and configure a cluster manager like YARN or Mesos to efficiently manage the cluster.
From there, developers can initialize the Spark environment and interface with Spark Core in their preferred programming language to operationalize the cluster in data processing. A Spark cluster can read data from various sources to power interactive SQL queries, train ML algorithms, or enable real-time streaming or GraphX processing.
AWS Analytics with Apache Spark
A second option for Spark users is to deploy the Spark cluster on AWS public cloud infrastructure. AWS offers a range of cloud services that integrate with Apache Spark to enable data processing at scale for diverse workloads and use cases.
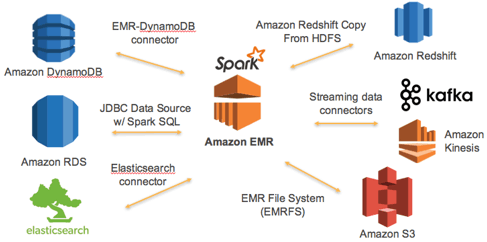
Spark integrations with data sources and cloud services on AWS.
These service include:
- AWS Glue - A fully managed data catalog and ETL service that integrates with Apache Spark to support automated schema discovery and data transformation.
- Amazon AMR - A managed cluster computing platform designed to support big data analytics frameworks like Spark and Hadoop.
- SageMaker - A fully managed ML service for training, deploying, and hosting ML models, SageMaker can leverage Spark for data prep and preprocessing.
- Amazon Athena - Amazon’s interactive query service integrates with Spark to enable serverless querying on top of Spark’s data processing capabilities.
- Amazon Redshift - AWS customers can build and run Spark applications on Amazon Redshift, as well as perform ultra-fast analytics on datasets stored in a Redshift data warehouse.
- Amazon Kinesis - Kinesis Data Firehose can ingest, transform, and deliver data directly to a cloud-deployed Spark cluster, while Kinesis Data Analytics integrates with Spark to enable real-time processing.

Apache Spark on Databricks
A third and increasingly popular way for organizations to leverage Apache Spark for big data analytics is through the Databricks platform. Founded in 2013 by the same research team that created Spark, Databricks has become the leading platform for data science and machine learning with over 10,000 customers and a valuation of $43 billion.
Databricks is powered by Apache Spark under the hood, but includes proprietary features that extend Spark’s functionality and make it easier to use. When customers deploy a compute cluster or SQL warehouse on Databricks, the Databricks platform automatically configures, deploys, and manages the Apache Spark cluster on virtual machines. This allows Databricks customers to leverage Spark’s data processing capabilities to support real-time streaming data, machine learning, and other workloads without the cost, risk, and complexity of managing Spark clusters and the related infrastructure.
READ: How to Get Started with a Security Data Lake
The Future of Apache Spark in Big Data Analytics
Spark Development Continues with the Upcoming Release of Spark 4.0
The upcoming release of Spark 4.0 will introduce a range of new features to the Spark framework, including new functional capabilities, extensions that enhance Spark interoperability with external applications and data sources, custom functions and procedures, and usability improvements.
Some of these include:
- A new Streaming State data source that allows users to inspect and even manipulate the internal states of streaming applications using familiar data source APIs.
- Support for pandas 2.x API.
- Support for streaming and batch python data sources with a simplified API that removes complicated performance features and makes it easy to use.
- Upgrades to PySpark that make it easier to use Spark from Python.
- New connectors enable out-of-box capability to read XML and Databricks SQL data.
- A new variant data type that supports semi-structured processing by flexibly storing semi-structured data without requiring the user to define a schema.
- A Materialized Views feature that improves query performance by storing the pre-computed results of complex queries to simplify future queries.
- Structured logging with JSON as the default format, making it easier to parse and analyze Apache Spark logs.
Spark 4.0 is still in development and may be released as soon as July 2024. A preview release of Spark 4.0 is now available for download on the Apache Spark website.
Developers Finding New Ways to Optimize Spark Efficiency
Along with new features and capabilities, contributors to Apache Spark are working on projects to enhance Spark’s performance and efficiency.
A current example is the Tungsten Project, a concerted effort to engineer changes to Apache Spark’s execution engine that would significantly improve the efficiency of memory and CPU usage for Spark applications. The Tungsten Project spans several initiatives, such as:
- Leveraging application semantics to improve memory management and binary processing.
- Placing intermediate data in CPU registers instead of in memory.
- Implementing new algorithms and data structures to exploit memory hierarchy.
- Eliminating virtual function dispatches to reduce multiple CPU calls.
- Optimizing Spark’s execution engine to take advantage of new capabilities and efficiencies present in modern compilers and CPUs.
These improvements will allow Apache Spark to process big data workloads even more efficiently by taking advantage of the most powerful modern hardware.
Spark Shifts Towards a Microservices Architecture with Spark Connect
Spark Connect is another new capability that’s changing how users deploy applications on Spark and enabling the shift towards microservice architectures for Apache Spark applications.
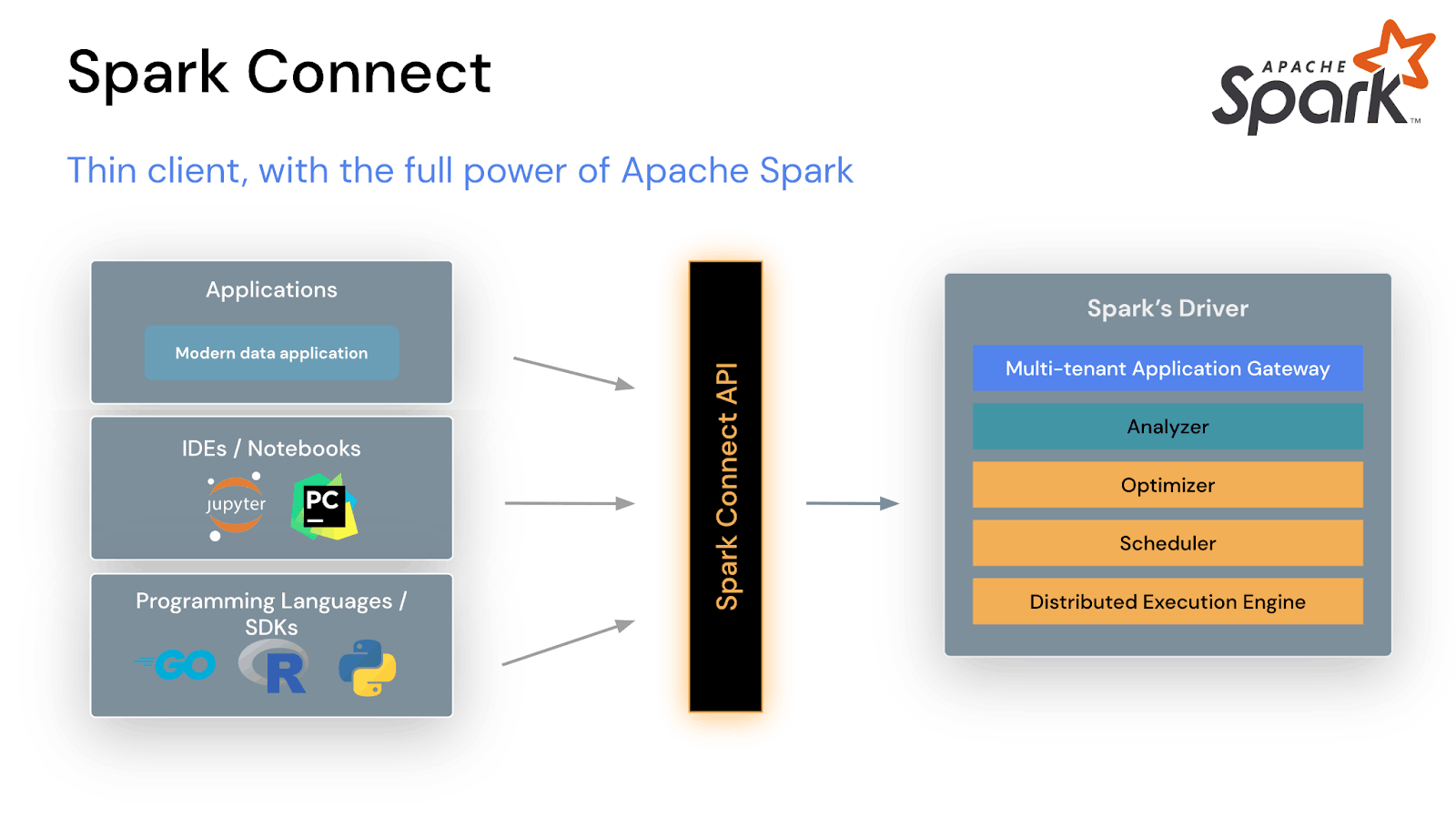
Spark Connect enables remote connectivity to Spark clusters, allowing for a decoupled client-server architecture that’s more efficient and flexible.
Spark was initially designed so that all Spark applications run on the same monolithic server cluster, creating dependencies between the application code and Spark cluster that restrict how users can debug or upgrade their applications and servers.
Spark Connect introduces a decoupled architecture to the Spark framework that isolates the user’s application code from Spark’s execution environment, enabling applications running anywhere to leverage Spark. This allows for easier debugging and more flexibility to separately upgrade Spark and application components. It will also enable microservice applications to better utilize Spark, and make it easier to deploy Spark applications on lightweight devices with less memory and CPU.
Build a Unified Lakehouse for Big Data Analytics with ChaosSearch on Spark
With one of the largest and most active open-source communities, Apache Spark is poised to remain a top choice for big data analytics in the cloud.
ChaosSearch recently announced new integrations with Databricks and Spark, empowering our customers to architect a unified data lakehouse solution that combines Spark’s distributed processing capabilities with the data ingestion, indexing, and security operations/threat hunting capabilities of ChaosSearch.
ChaosSearch is now Spark native, so our customers can run ChaosSearch on their Spark environment to take advantage of our data ingestion and query planning alongside Spark’s distributed processing capabilities.
ChaosSearch has also become a Databricks Technology Partner and Databricks customers can now deploy ChaosSearch on the Databricks platform.
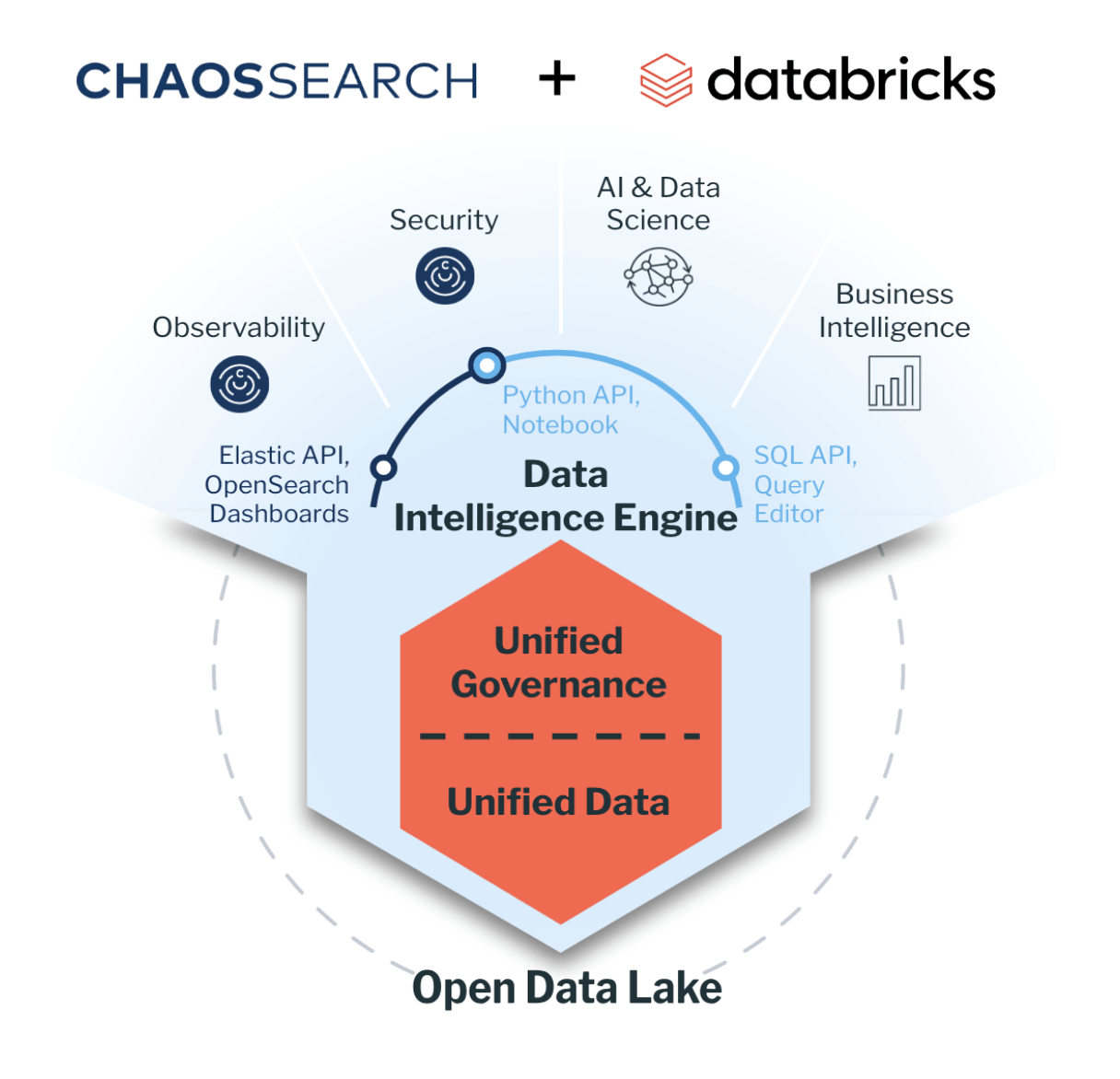
ChaosSearch brings log analytics, flexible live ingestion, full-text search, and unlimited cost-effective cloud data retention to the Databricks ecosystem, while Databricks enables an AI or ML-driven approach to enterprise cloud observability and security.
Ready to learn more?
Read the Extend Your Databricks with ChaosSearch Solution Brief to explore how you can bring log analytics and ELK use cases to Databricks with ChaosSearch.

