

Streaming analytics in AWS gives enterprises the ability to process and analyze log data in real time, enabling use cases that range from delivering personalized customer experiences to anomaly and fraud detection, application troubleshooting, and user behavior analysis.
In the past, real-time log analytics solutions could process just a few thousand records per second and it would still take minutes or hours to process the data and get answers.
But with innovations like cloud computing, data-driven organizations are turning to public cloud providers like AWS for the next generation of streaming analytics tools that can handle large volumes of log data generated continuously from thousands of sources, and deliver fast, high-performance analytics.
In this blog, we’re taking a closer look at streaming analytics in AWS. We’ll explore the capabilities available for AWS customers when it comes to streaming analytics, including Amazon’s data streaming tools, how to consume streaming data in AWS, the limitations of streaming analytics, and how ChaosSearch can complement your streaming analytics initiatives.
What is Streaming Analytics in AWS?
When it comes to processing and analyzing log data, organizations have two basic choices: streaming analytics, or batch analytics.
In batch analytics, log files are collected and stored for a period of time before being fed into an analytics system. Batch analysis means that your log data is already minutes or hours old when it reaches your analytics tool. This data is too old to support real-time analytics use cases, but can support long-term use cases like root cause analysis or advanced persistent threat detection.

Batch vs. Stream data processing in AWS.
In streaming analytics, newly generated logs are continuously fed into the analytics system and immediately processed (within seconds or milliseconds) to support near real-time log analytics use cases. Processing log data in real-time means that enterprise IT and SecOps teams can promptly identify and react to anomalies, security incidents, or application issues that threaten to negatively impact the customer experience.
Read: How to discover advanced persistent threats in AWS
Streaming Analytics in AWS with Amazon Kinesis
If you’re doing streaming analytics in AWS, you’re probably using Amazon Kinesis. Kinesis gives AWS customers the ability to easily collect, aggregate, process, and analyze data streams in near real time, at any scale, and with the flexibility to consume the data in different ways depending on application requirements.
Here’s a quick summary of four Amazon Kinesis capabilities and how they enable streaming analytics in AWS.
Kinesis Data Streams
Amazon Kinesis Data Streams is a serverless streaming data service that allows AWS customers to capture, process, and store data streams from a variety of sources at any scale.
With Kinesis Data Streams, AWS customers can:
- Ingest terabytes of log data each day from applications, web services, in-app user events, IoT devices, and other log data sources.
- Process the log data to generate metrics or power customized video dashboards in a preferred analytics tool.
- Deliver log data into an Amazon S3 data lake for long-term storage,
- Run analytics in real-time to generate insights from log data in seconds, and
- Power event-driven applications that respond or adjust their behavior based on data from event logs.
Kinesis Data Firehose
Amazon Kinesis Data Firehose is an Extract, Transform, Load (ETL) service with the ability to capture, transform, and deliver streaming log data to data lakes, data warehouse deployments, data stores, and other analytics tools.
AWS customers can use Amazon Kinesis Data Firehose to:
- Aggregate and transform data before delivering it to a data lake or data warehouse for further analysis.
- Deliver log data into a SIEM tool to enable network security monitoring, alerting, and incident response.
- Deliver log data to a machine learning (ML) algorithm to drive the development of predictive models.
When creating a delivery stream with Kinesis Data Firehose, AWS customers can use the Direct PUT option to write data directly to a data stream from a data-producing application. Many AWS and open-source services are integrated with Direct PUT, including:
- AWS SDK
- AWS Lambda
- AWS CloudWatch Logs and Events
- AWS Cloud Metric Streams
- Amazon SNS
- Amazon API Gateway - Access logs
- Kinesis Agent (Linux)
- Kinesis Tap (Windows)
- Fluentbit
- Fluentd
- Apache Nifi
Supported destinations where Kinesis Data Firehose can send data include Amazon OpenSearch Service, Amazon Redshift, Amazon S3, Coralogix, Datadog, Dynatrace, New Relic, Splunk, Sumo Logic, and MongoDB Cloud.
Kinesis Data Analytics
Kinesis Data Analytics gives AWS customers the ability to capture streaming data from a variety of sources and process the data in real-time using SQL or Apache Flink before sending the output to an Amazon S3 data lake, Amazon MSK, or another destination.
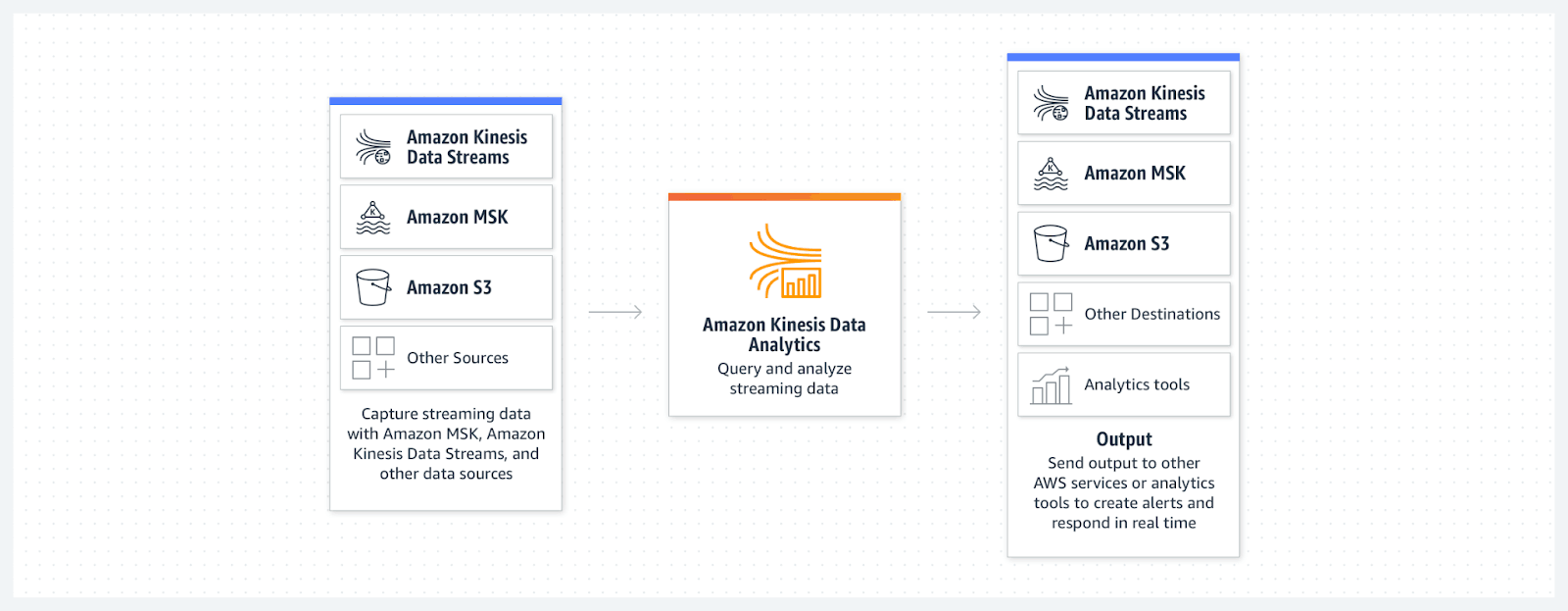
Streaming analytics architecture using Amazon Kinesis Data Analytics.
Consuming Streaming Data in AWS
Amazon Kinesis enables AWS customers to collect, process, and deliver a continuous stream of log data from upstream data sources to downstream data storage and analytics tools. With Kinesis Data Firehose, AWS customers can deliver streaming data directly into Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and Splunk without having to write any custom code.
Let’s take a closer look at how enterprises can utilize these four different options for consuming streaming data in AWS.
Amazon S3
Amazon S3 provides massively scalable, reliable, and cost-effective cloud object storage for enterprise log data - 99.999999999% (11 9's) of reliability to data stored in S3. AWS customers can stream log data into Amazon S3 to establish a security data lake, supporting log analytics use cases like advanced persistent threat detection, fraud detection, and root cause analysis.
For organizations retaining log data for compliance purposes, Amazon S3 offers cost-effective data archiving via its tiered storage capability.
Amazon Redshift
Amazon Redshift is a fully managed high-scale data warehouse service that deploys in the cloud. AWS customers can use Kinesis Data Firehose to collect log data from multiple sources and transform it into a structured/tabular format before sending the data to an Amazon Redshift data warehouse.
Once the log data reaches Amazon Redshift, analysts can query the data with their existing SQL-based tools and business intelligence (BI) applications. Typically Redshift is not a target for Logging Applications and used as a traditional data warehouse.
Amazon OpenSearch Service
OpenSearch is an open source search and analytics tool based on Elasticsearch that makes it easy for AWS customers to perform interactive log analysis and monitor the health of applications and cloud infrastructure in real-time.
In addition to application monitoring, Amazon OpenSearch Service enables log analytics applications that include anomaly detection, security information and event monitoring (SIEM), and observability.
Read: Integrating Observability into Your Security Data Lake Workflows
Splunk
Another option for AWS customers using Kinesis Data Firehose is to load data streams directly into Splunk.
Splunk delivers observability and alerting capabilities that help enterprises monitor the health of cloud services and infrastructure, troubleshoot application performance issues, optimize cloud costs, and even track user behavior in real time.
Read: Complement Splunk with a Security Data Lake
What are the Limitations of Streaming Analytics in AWS?
When it comes to streaming analytics in AWS, the most significant limitations are the complexity of building and maintaining data pipelines and the cost of processing, storing, and analyzing data at scale.
Log data is generated from a variety of sources in many different formats. To make use of this data in real-time applications, developers must build customized data pipelines to gather data from the source, transform the data to a desirable format, and send it to the appropriate analytics tool. This process increases in cost and complexity as the number of log sources increases.
The cost of analyzing log data at scale using currently available platforms is another limitation of streaming analytics. For organizations generating log data at petabyte scale, transforming and ingesting the data into an analytics tool like Splunk becomes prohibitively expensive.
Organizations can try to reduce costs by shortening the data retention period in Splunk to a week or just a few days, but purging data from analytics tools so quickly after ingestion means that it can no longer be used to support longer-term analytics use cases.
Analyze Streaming Data at Scale with ChaosSearch and AWS
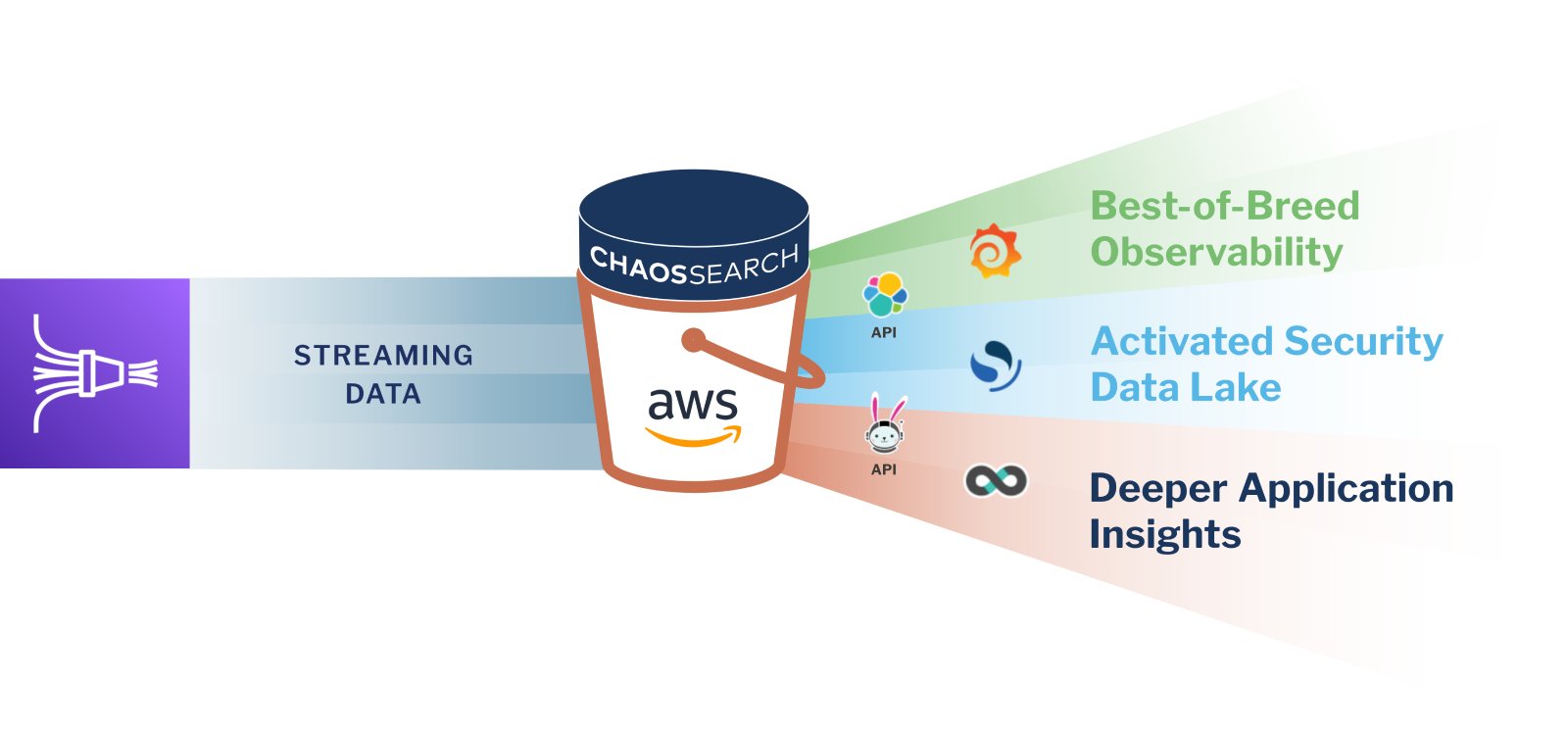
ChaosSearch can harness the power of AWS Kinesis immediately as ChaosSearch transforms your Amazon S3 into a log analytics data lake, giving you the ability to cost-effectively store and analyze log data in AWS with multimodal data access (SQL, Search, and ML), no unnecessary data movement, no fragile and time-consuming ETL pipelines, and no limits on data retention.
AWS customers can use Kinesis Data Streams to ingest logs from multiple sources and deliver them to Amazon S3 cloud object storage at scale. Once the log data lands in S3, ChaosSearch can index the data with proprietary indexing technology and up to 20x file compression, rendering the data fully searchable.
ChaosSearch users can trigger the indexing process after creating an object group in S3, or take advantage of ChaosSearch Live Indexing capabilities to monitor Amazon S3 for new object creation events and automatically index the newly-created log data to make it available for querying.
Once your log data has been indexed with ChaosSearch, Chaos Refinery® lets you create virtual views to analyze and visualize your data in different ways with no data movement and no changes to the underlying log data.
While monitoring and observability tools like Splunk provide real-time analytics on streaming data, ChaosSearch enables scalable analytics directly out of S3 with near-real-time access to data as it streams and support for long-term log analytics use cases that would be cost-prohibitive in other platforms.
Ready to learn more?
Start a free trial of ChaosSearch and see how easy it is to:
- Transform your Amazon S3 cloud object storage into a hot analytical data lake,
- Stream log data into your new data lake with Amazon Kinesis Data Streams,
- Index your data, build views, and create data visualizations using ChaosSearch.


